
咨询热线:
020-88888888
020-88888888

考虑如下带等式约束的最优化问题 类似于无约束最优化问题,极值点处的一阶必要条件有:
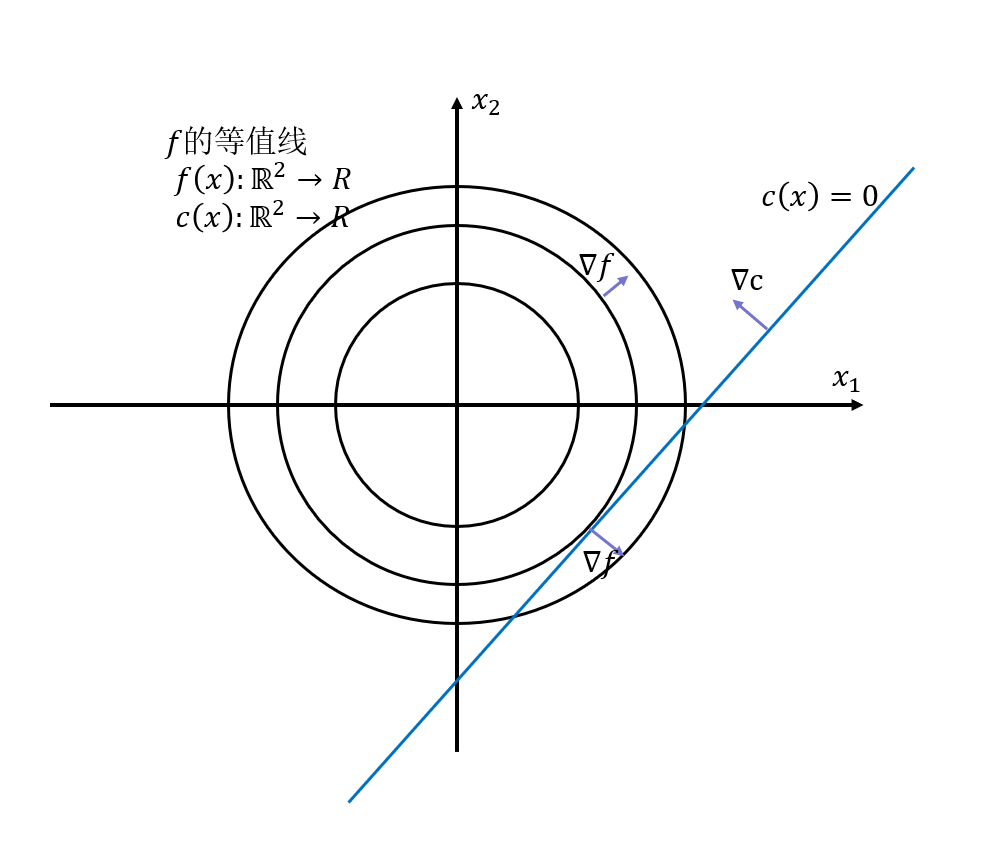
第一点换句话说,的方向必须要是不自由的方向,在自由方向不能有分量,因此,
的方向要垂直于约束流形(constraint manifold)的方向。
在
是向量的情况有,
基于此我们定义拉格朗日函数,包含
两个变量。
现在对这个函数的两个变量求导,正好可以得到
对应上面提到的两个一阶必要条件,这也是等式约束下的KKT条件。
ps:一般的课可能讲到这里就停了,因为对于我在学校学的那些简单函数说,这两个条件列出的所有方程有时候就可以全部解析的求出所有的和
了,然后再判断各个点是不是极小值点,得到全局的极小值。但是对于实际许多复杂的非线性函数而言,式(5)无法解析求得,需要用迭代求根的方式来求解局部极小值。
现在要解(5)的方程,使用牛顿法,因为这里有两个变量和两个输出(并不一定二维),对(5)式进行一阶泰勒展开,并令其为0(因为是求根),得到(5)的根的迭代式子,也就是(4)的局部极值点的迭代式子(回忆一下,在Lecture 4中介绍单变量的牛顿法,我们也是那么做的) 注意,从(5)的第二条式子中,可以得
,最终,得到
的迭代式
前面这个大矩阵正是拉格朗日函数的Hessian矩阵,这个系统称为KKT系统。
ps:因为这个矩阵长得比较特殊也比较通用,因此,教授课上说有许多针对性的求解器来迭代这个方程。
式子(7)中有一项对求二阶导数,而后面那项要对约束求二阶导,在实际的问题中,
是期望的目标函数,可以设计地比较规范,而
是约束,来自实际的物理系统,往往比较复杂也比较难以微分,因此,在对式子(7)迭代时候,可以考虑丢弃(8)中的第二项,这种方法叫做高斯牛顿法。
高斯牛顿法等价于先对系统线性化后在求解线性化后的系统的极值点。
使用牛顿法和高斯牛顿法分别对下图所示的问题进行最小化。其中,一圈一圈的是目标函数的等值线,黄色的抛物线是约束。可以看出,牛顿法在不合理的起始点(-3,2)中,反而有可能无法收敛于极小值点。而高斯牛顿法不存在这个问题,因为高斯牛顿法去掉第二项之后,保证Hessian矩阵是正定的,因此,每一步迭代都是向着下降的方向迭代。虽然从理论上牛顿法在靠近极值点附近收敛更快,但是实际来看,高斯牛顿法表现地更加稳定。
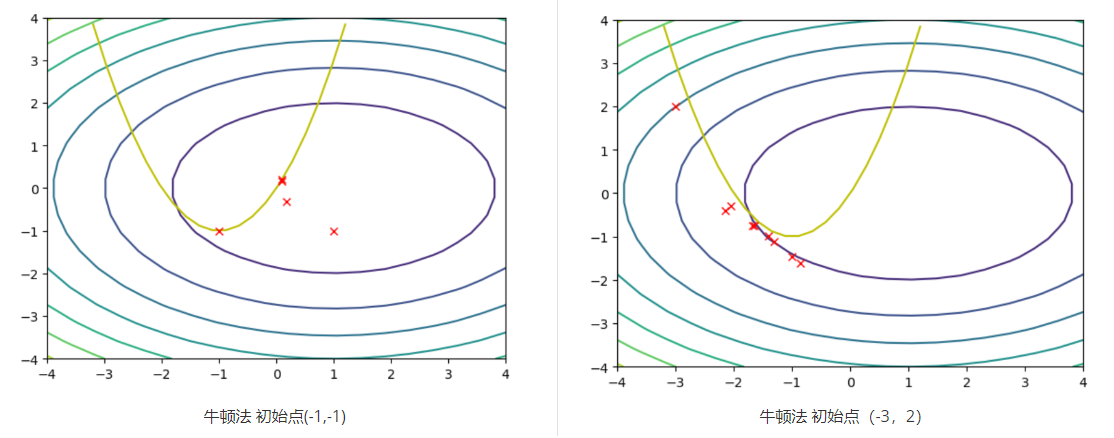
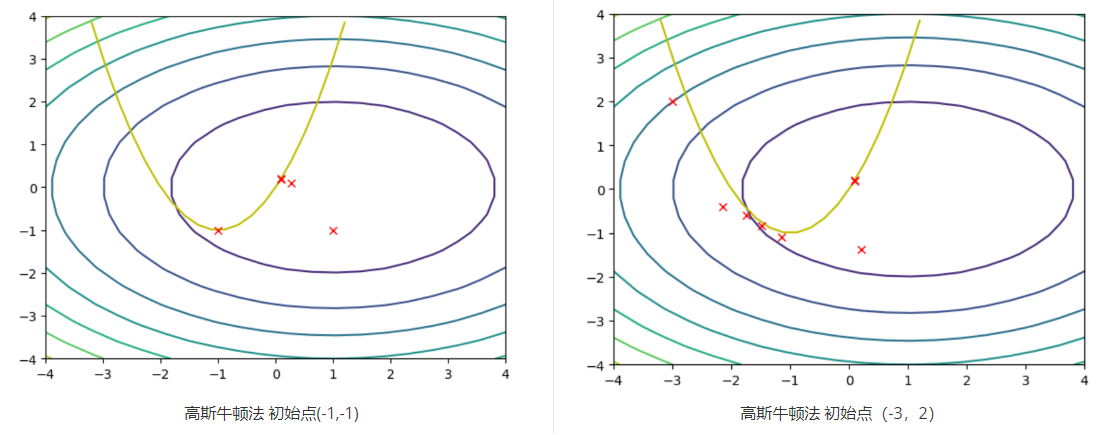
ps:从迭代的过程中来看,在迭代过程中并不是一直被满足的,但是,假如迭代收敛,那么最终一定会在约束上。
考虑如下带约束优化问题, 极值点处的一阶必要条件同样是:
但是,要从数学上表示这两个条件,不等式的情况比等式的情况要复杂的多。 第四个条件互补松弛条件,表明
和
至少要一个为0。
从(10)中可以看出,不等式约束的一阶必要条件在数学上是比较复杂的,而且还因为互补松弛条件引入了非常强大的非线性,甚至是一种if-else的逻辑,因此要求解(10)得到极小值点是比较复杂的。我们只能另辟蹊径。
并且,KKT条件只是告诉我们,在极值点处会是一个怎样的情况,并没有说如何迭代或者如何优化才能到极值点,因此具体如何解这个问题,以及各个case怎么处理,要看具体的求解器。
这里老师并没有详细讲,抽空详细补充一下。
核心想法:找一堆guess heuristic function来不断猜测哪些不等式约束是生效的(等式约束),找到之后,不生效的约束则不作任何处理(当作没有),则按照只有等式约束的问题来迭代一次,之后继续判断哪些集合是生效的。
核心想法:把约束转换成cost,这个cost由一个barrier function表示,在违反约束的时候给一个很大的cost。
如常用的障碍函数

核心想法:把约束转成惩罚项,同样加到cost中。

ps:课上有同学提问,能否使用罚函数法或者内点法求解一段时间,再利用这个结果切换到积极点法中求解。老师回答说,这是工程上常用的技巧,先使用惩罚项来polish问题。
由于罚函数法存在的一些问题,我们转向增广拉格朗日法,核心想法是:我们在内层优化关于x的函数,在外层更新拉格朗日乘子来卸载(offloading)惩罚项
增广拉格朗日函数为: 将该函数对
求导,有

在初始时,令,表示所有约束都不active,而后做一次无约束的最优化(关于
),判断有哪些约束被违反了(active),若有违反,则更新对应的拉格朗日乘子(拉格朗日乘子有值后才会在
项中存在惩罚),则在下一次的最优化中,就会有满足这个约束的趋势,一直迭代到收敛。
因为是约束,在约束违反时候(
),
外层的更新是为了不断增大惩罚力度,
例子中是一个经典的QP问题,利用增广拉格朗日法解不等式约束。
function newton_solve(x0,λ,ρ) # 这个函数不改变lambda和rho
x = x0 # 问题是min x^2+2*y^2 约束是x-y+1=0 问题是二维的
p = max.(0,c(x)) # 注意这个p和ρ是不同的,并且在这里例子中,约束是 c(x) <=0
C = zeros(1,2) # 所以要cost中的λ是正号才能惩罚违反约束的情况(c(x) > 0)
if c(x) ≥ 0 # 由于问题只有一个约束,若违反的话,那就设置梯度,用于优化
C = ?c(x)
end
g = ?f(x) + (λ+ρ*p)*C' # 最终要优化的是关于x的拉格朗日函数,因此要对其求导,然后找根
while norm(g) ≥ 1e-8
H = ?2f(x) + ρ*C'*C # Hessian阵,内层环不优化lambda,因此只有x
Δx = -H\\g
x = x+Δx
p = max.(0,c(x)) # 对应问题的最后一项
C = zeros(1,2)
if c(x) ≥ 0
C = ?c(x) # 同样迭代完后判断有没有违反。没有违反就不要继续优化了,消掉COST和梯度
end
g = ?f(x) + (λ+ρ*p)*C'
end
return x
end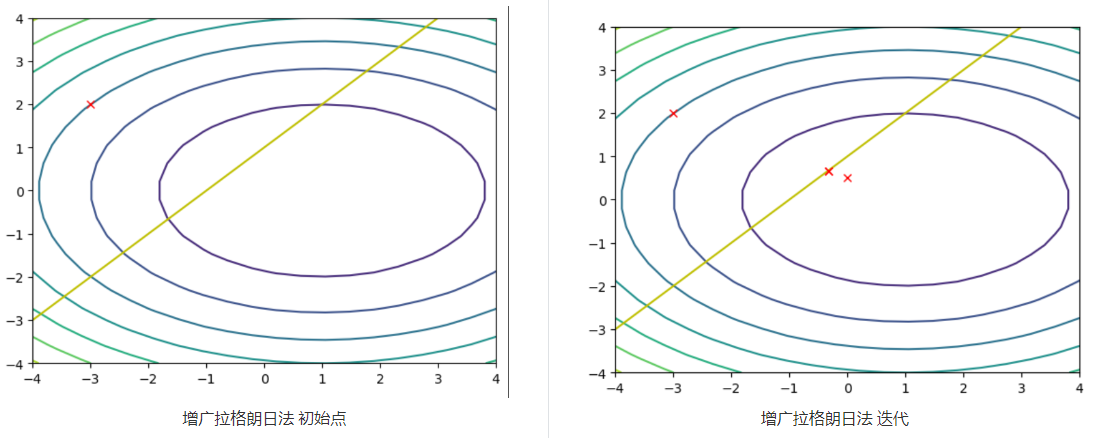
在这个例子中,即使外层不更新也能收敛
Copyright © 2002-2022 恩博-恩博娱乐沙盘模型研发站 版权所有 非商用版本 备案号:额ICP备5412147号">额ICP备5412147号


